Using a tiered uGPT approach for Ultimate Bots
In this article I'll dive into a way to use generative replies based on multiple data sources, while making sure your AI Agent uses your best sources first, before using secondary resources to fill in the gaps.

Using a tiered uGPT approach for Ultimate Bots
In this article I'll dive into a way to use generative replies based on multiple data sources, while making sure your AI Agent uses your best sources first, before using secondary resources to fill in the gaps.

On this page
Zendesk's Advanced AI Agents can pull information from multiple sources. They can index your Help Center, your website, webshop or a myriad of other resources.
This gives you the benefit that, once indexed, your AI Agent can basically respond to any type of inquiry as long as you've written about the topic somewhere.
But not all resources are equal though. Where your Help Center focused mainly on how customers can do something, your website will mostly focus on why a customer should buy the product. And your webshop will focus on features of those products.
So imagine a customer asking about a password reset. Logically, the only place information related to that use case can be found is your Help Center, and the customer will get a generated response about their inquiry.
If a customer asks about the type of services you offer, your AI Agent will probably look at your website and give your customer a summary of your Our Services page. And a customer asking about the difference between your Pro and Base models will (hopefully) get good summary based on those product pages from the webshop.
But what happens if you have a webpage on your website, webshop and knowledge base about the same topic. Each has a focus, namely marketing and winning new customers, closing deals and selling items, and helping customers with your inquiries. When your customer contacts you via your AI Agent it'll be mainly for support reasons. So you kinda want your AI Agent to pull from the Help Center pages first, and only resort to those other context types when the knowledge base ends up empty..
There's another scenario where this kind of ranked sources might be useful. Customers who just start with AI Agents and Self Service might have a lot of low quality content from legacy solutions, internal resources, data sources from agents and so on. Getting all this data up to date is a major task and a core element of a good approach to Self Service. So you might want to focus on getting first a set of data up to date and pushing that data to customers first, and then, and only of that data is not useful to provide an answer, fall back to lower quality response sources. Those articles will then show up in reporting as part of knowledge gaps or content to improve, giving you good pointers on where to focus next.
A few ways to resolve this
An expected solution
When looking at this problem from a distance you might see an obvious solution. We tag each imported data-source with a priority, which will tell the bot "look at the highest priority sources first, and then dive down into the other ones".
Google uses similar ranking systems for example where highly trusted websites, or pages that get linked to a lot (or buy sponsored spots via ads...) will show up higher in results than other sources.
Sadly, Ultimate has no such feature. It solely looks at the actual use case of the message and matches that with the article that matches that question closest across all imported data. (There's other heuristics at play I assume but for simplicity let's keep it at that).
A micromanaging solution
Another approach might be to have Ultimate index your website, webshop and help center, but then go into the indexing rules and manually add any URLs that have overlapping or low quality content so only the good ones remain.
Each time you update content you can then dive into the importer and add or remove those new URLS so that they get imported.
This will make sure you only index good content, but is resource intensive from a managing perspective since you need to almost add your sources one page at a time.
A flow based solution.
By default Ultimate's uGPT flow works like this:
- A customer asks a question
- Ultimate checks via a uGPT block if an answer can be found in its indexed sources
- The answer is shared to the customer
- If no answer is found we link to the Not understood flow where we can ask the customer to rephrase
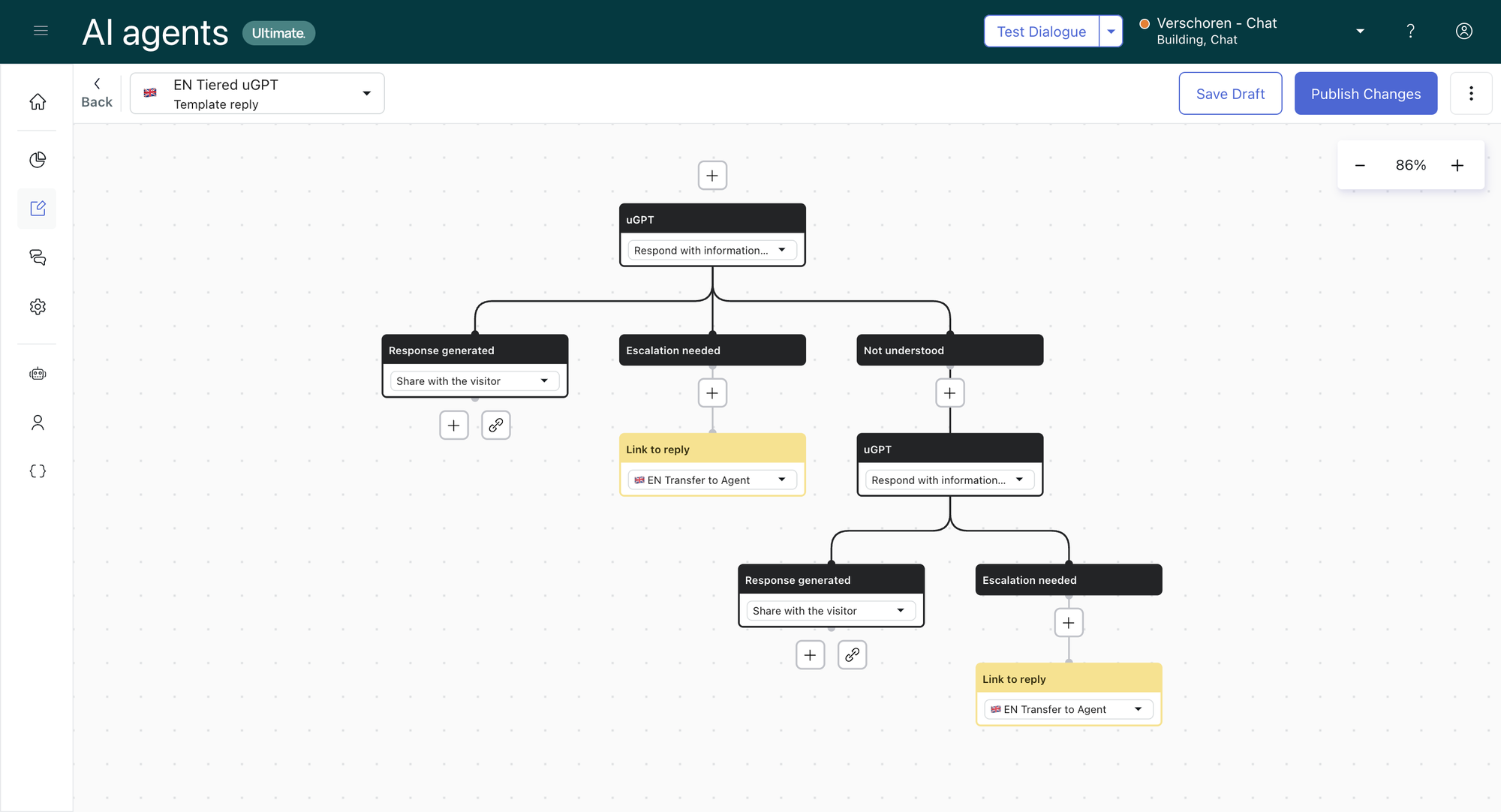
But what if instead of doing a single uGPT block, we run that flow twice.
The first run we only check a set of primary sources we know has good quality content. This filter can be created as a search rule in the uGPT settings.
If the first uGPT block finds an answer, we share it with the customer, knowing it's the best version of the answer we'll find.
We can then disable the default Not understood reply in our flow. This will make that conditional step show up in our flow. In that conditional step we can add a second uGPT block that does look at all content. Here too, if it does finds an answer it'll share it with the customer, and if not, we'll point the customer to the Not understood flow. The customer might get an answer, but we can sure that if a better answer was available in the primary sources they'd gotten that one, and now they only get a reply from a lesser quality source. They might for example get a more commercial reply to their inquiry than an actual troubleshooting step. Or they might get a response from articles that still reference older software versions but do contain good edge cases,...
This additional step does introduce a small delay in the flow since we need to run uGPT twice, but it's barely noticeable.
Creating a search filter
You can create a search filter via Settings > ultimateGPT > Search rules.
In this scenario I created a Primary ruleset that only indexes my website (blog) and help center.
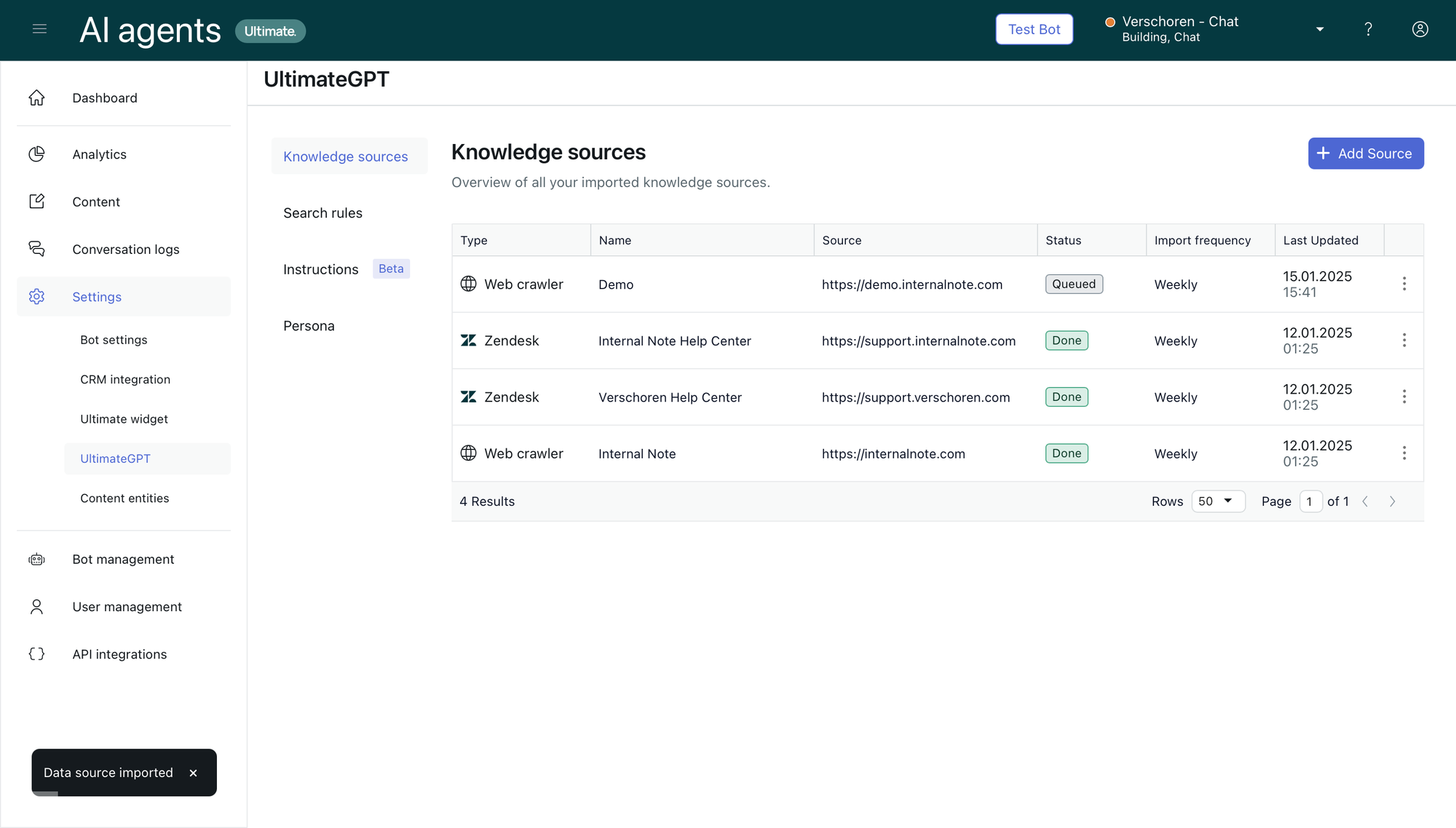
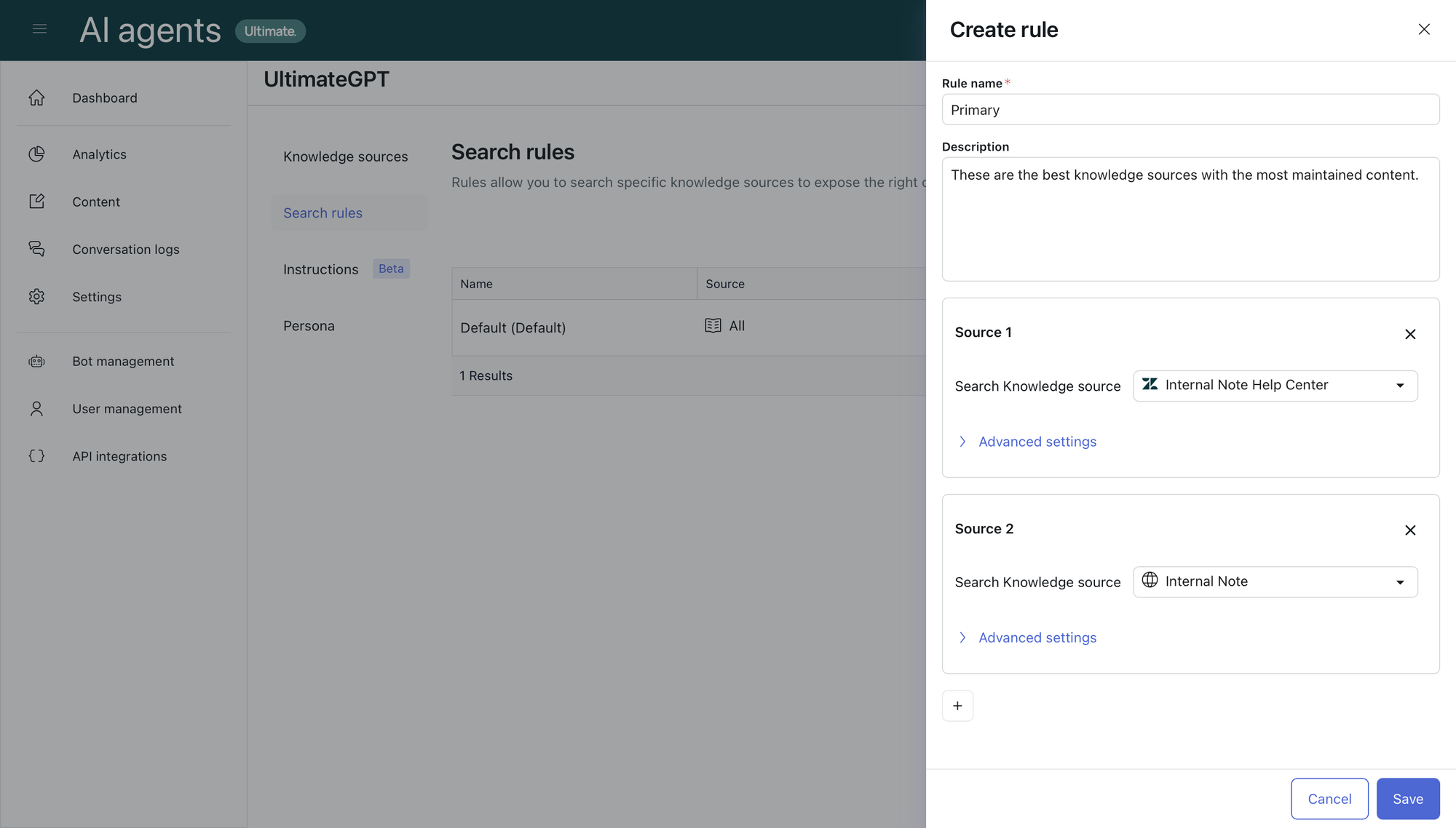
A list of all sources, and a search rule that only looks at the Blog and Help Center
Building the flow
You can easily build this tiered uGPT flow by modifying your existing uGPT flow.
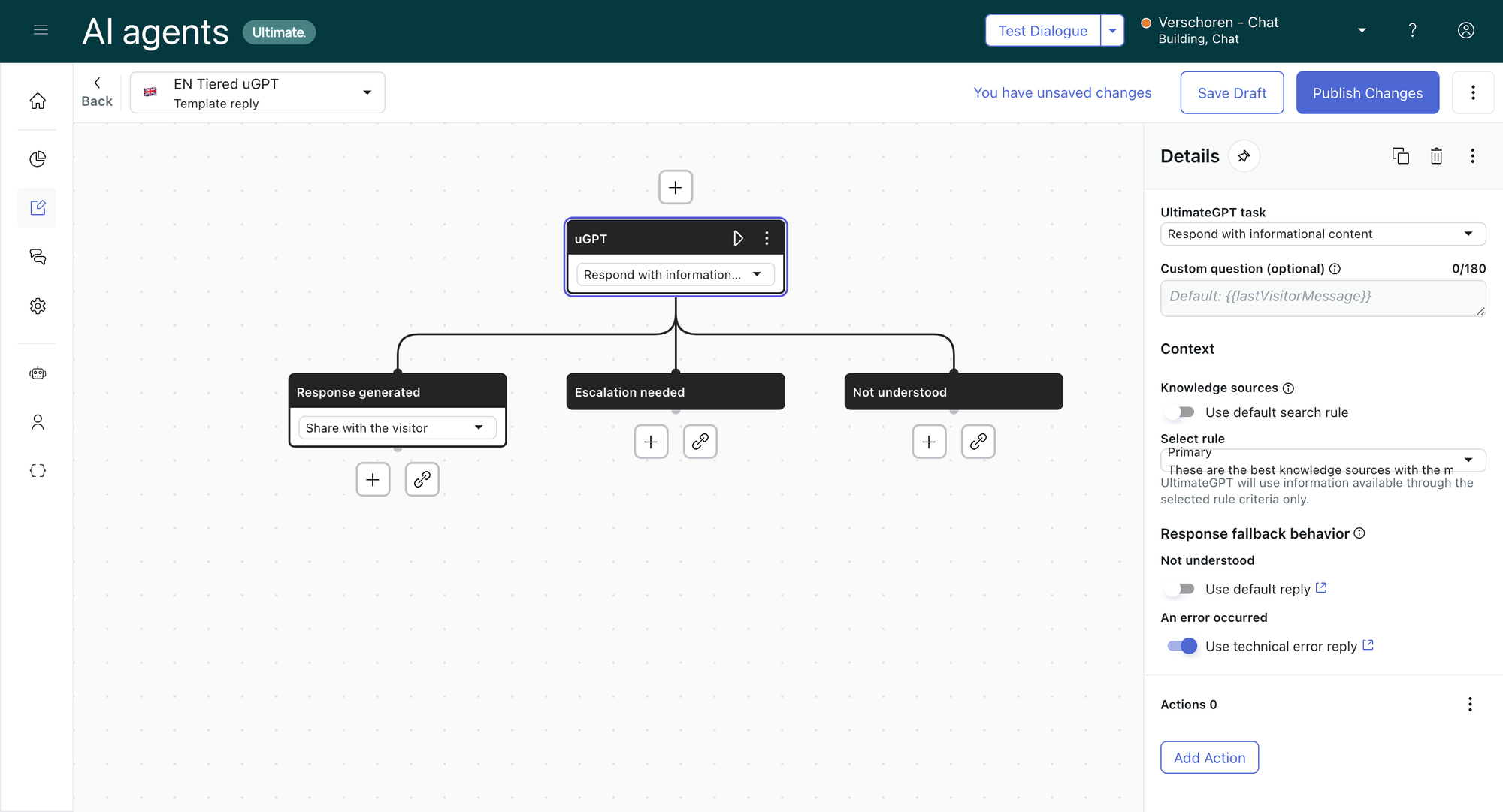
You need to make two modifications to the first uGPT block:
- Disable the Response fallback behavior for Not Understood
- Disable the default rule in Knowledge source and select our custom Search Rule in the dropdown
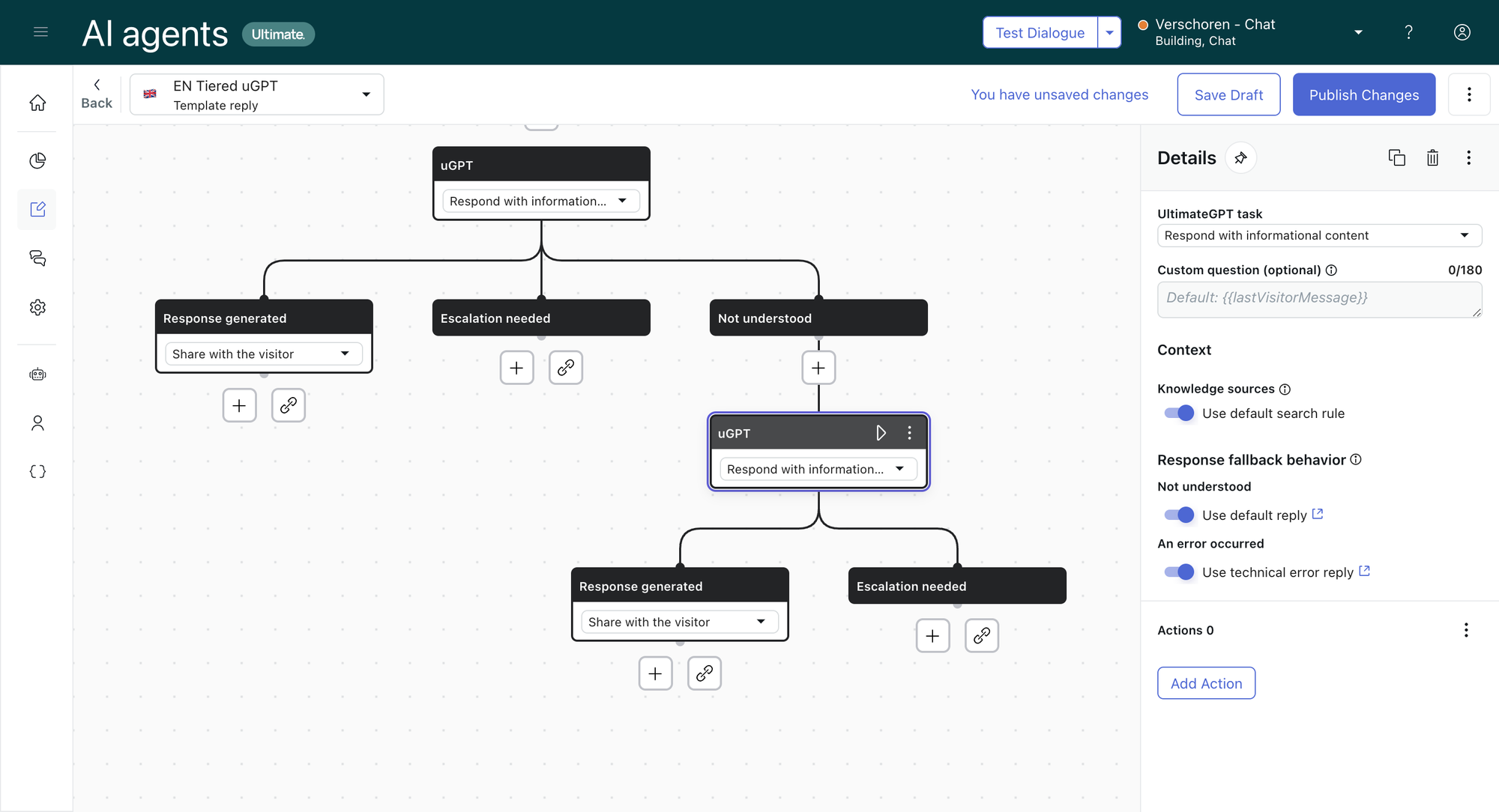
You need to add a new uGPT block in the Not understood branch. This block can keep its default settings.
Conclusion
It's a bit of a hack, and I wouldn't advise anyone to use this unless you run into the issues mentioned above of having clearly subpar content that is the sole source of that data. But in those cases, introducing a tiered uGPT approach is gold. It improves the quality of your primary sourced replies, while still offering a wider range of answers to conversations that would otherwise all go to your agents via escalation.